
A break from our compliance articles, here is a simple hack for a problem plaguing us for some time. Our backup program is fairly comprehensive…we use a lot of different backup options. We are of the philosophy that you can never back up enough. Never. And anyway, PKF Malaysia is pretty big. We have offices in KL, Penang, Ipoh, KK, Sandakan, KB, Cambodia under us. That’s a lot of data. One of the backup options we use is automated to large external USB drives for archival.
While not the primary means of backup, it’s still pretty frustrating when we faced a strange issue with two of our external drives acting up all of a sudden. We don’t know why. They were working well enough, but suddenly, just stopped functioning well. Like a teenage kid. What happened was, we found that backups would regularly hang to the external drives (we have 2 of the same brand). At first, we thought it was just a connection issue (USB failing etc) and we took them out and tried it on various Windows servers (not *nix as we didn’t want to mess around with those, as they were critical). The idea anyway was to have these function on Windows only. Same issue was observed on all Windows servers and even on workstations and laptops.
The issue was simply excruciatingly slow transfer speeds and a graph looking similar to this:
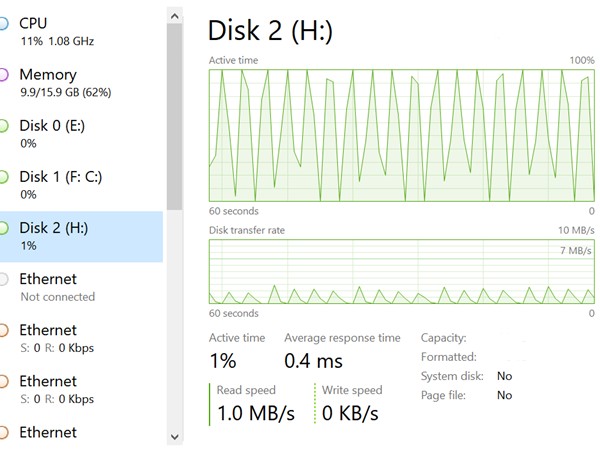
Now that doesn’t look like a healthy drive.
What is happening here was that it would start whirring up once we tried to transfer files and the active time of the disk would be 1%. In a second, it would hit 50% and then within 2-3 seconds hit 100%. At that moment, the transfer speed had probably crawled up to around 15-20 MB/s and it would drop again to zero as the disk starts to recover. And it would happen again and again. This made data transfers impossible, especially big backups we did.
Troubleshooting it, after we tried updating firmware to no success:
a) Switched cables for the drives: Same issue
b) Switched servers / workstations : Same issue. We note we didn’t try it on *nix because those were critical to us but as an afterthought, it was probably something we could have done to isolate if the problem was the drive or the OS.
c) Switched other external drives: Works fine. So we kept one of these older drives as a control group so we know what is working
d) Switched USB3.0 to USB2.0: This is where we began to see something. The USB2.0 switch made the drives work again. However, transferring at USB2.0 speeds wasn’t why we purchased these drives anyway, but again, this is a control group, which is very important in troubleshooting as it provides a horizon reference and pinpoint to us where the issue is.
We ran all the disk checks on it and it turns out great. Its a healthy drive. So what is the issue?
We opened a support ticket to the vendor of this drive and surprisingly got a response within 24 hours asking us the issue asking us for the normal things like serial number, OS, error screens , disk management readings etc. So we gave and explained everything and then followed up with:
We have already run chkdsk, scannow, defrag etc and everything seems fine. Crystaldisk also gave us normal readings (good) so we don’t think there is anything wrong with the actual drive itself. We suspect it’s the UASP controller – as we have an older drive running USB (Serial ATA) which was supposed to be replaced by your disk – and it runs fine with fast transfer speed. We suspect maybe there is to do with the UASP connection. Also we have no issues with the active time when running on the slower 2.0 USB. Is there a way to throttle the speed?
We did suspect it was the UASP (USB Attached SCSI Protocol) that this drive was using. Our older drives were using traditional BOT (Bulk Only Transport) and the USB3.0 was working fine. Apparently UASP was developed to take advantage of the speed increases of USB3.0. I am not a storage guy, but I would think UASP is able to handle transfers in parallel while BOT handles in sequential. I would think UASP is like my wife in conversation, taking care of the kids, cooking, looking at the news, answering an email to her colleague, sending a whatsapp text to her mum and solving world hunger. All at once. While BOT is me, watching TV, unable to do anything else until the football game is over. That’s about right. So it’s supposed to be a lot faster.
How UASP works though is it requires both the OS and the drive to support it. The USB controller supporting this in Windows is the uaspstor.sys. You can check this when you look at the advanced properties in device manager and clicking on the connected drive or through disk management screen and view the detailed properties. Interestingly, our older drives loaded usbstor.sys which is the traditional BOT.
UASP is backward compatible to USB2.0, so we don’t really know why USB2.0 worked while USB3.0 didn’t. The symptoms were curiously the same. Even at USB2.0, the active time would ramp up, but we think, because USB2.0 didn’t have enough pipe to transfer, the transfer rates were around 30 MB/s and the active time of the drive peaked around 95%. So because it never hit the 100% threshold for the drives to dial down, we don’t see the spike up and down like we see in USB3.0. However, active time of 90+% still isn’t that healthy, from a storage non-expert perspective.
The frustrating thing was, the support came back with
Thank you very much for the feedback. Regarding to the HDD transferring issue, we have to let you know that the performance of USB 3.0 will be worse when there is a large amount of data and fragmented transmission. The main reason is the situation caused by the transmission technology not our drive. For our consumer product, if the testing result shown normal by crystaldiskinfo, we would judge that there is no functional issue. Furthermore, we also need to inform you that there is no UASP function design for our consumer product. If there are any further question, please feel free to contact us.
One of the key things I always tell my team is that tech support, as the first line of defence to your company MUST always know how to handle a support request. The above is an example how NOT to be a tech support.
Firstly, deflecting the issue from your product. Yes, it may be so that your product is not the issue. But when a customer comes to you asking for help, the last thing they want to hear is, “Not my problem, fix it yourself.” That’s predominantly how I see tech support, having worked there for many years ourselves. We have a secret script where we need to segue the complaint to where we are no longer accountable. For instance – did you patch to latest level? Did you change something to break the warranty? Did you do something we told you not to do in one of the lines amongst the trillion lines in our user license agreement? HA!
So no, don’t blame the transmission technology. Deflecting the issue, and saying the product is blameless is what we in tech support call the “I’ll-do-you-a-favor” manoeuvre. Because here, they establish that since they are not obligated to assist anymore, any further discussion on this topic is a ‘favor’ they are doing for you and they can literally exit at any point of time. It makes tech support look good when the issue is resolved and if the going gets too tough, it’s not too hard to say goodbye.
Secondly, don’t think all your clients are idiots. With the advent of the internet, the effectiveness of bullshitting has decreased dramatically from the times of charlatans and hustlers peddling urine as a form of teeth whitening product. They really did. Look it up. Maybe, a full drive would have some small impact to the performance. But a quick look at the graph shows a drive that is absolutely useless, not due to a minuscule performance issue but to an obvious bigger problem. I mean how is it that we can make a logic that once it reaches a certain percentage of drive storage it is rendered useless?
Lastly, know your product. Saying there is no UASP function is like us telling our clients PCI-DSS isn’t about credit cards but about, um, the mating rituals of tapirs. The tech support unfortunately did not bother to get facts correct, and the whole response came across as condescending, defensive and uninformed.
So now, we responded back:
I am not sure if this is correct, as we have another brand external drive working perfectly fine with USB3.0 transmission rates, whether its running a file or transferring a file to and from the external drive. Your drive performance is problematic when a file was run directly from the drive, and also transmission to copy file TO the drive. As we say, the disk itself seems ok but regardless, the disk is not usable when connecting to our USB 3.0 port, which most of our systems have, that means the your external drive can only work ok for USB 2.0. We suggest you to focus the troubleshooting on the UASP controller.
Further on, after a few back and forth where they told us they will recheck we responded
Additional observation: Why we don't think its a transmission problem, aside from the fact other drives have no issues, is that when we run a short orientation video file from your drive, your drive active time ramps up to 100% quickly - it goes from 1% - 50% - 100%, then the light stops blinking, and it drops back to 1% again, and it ramps up again. This happens over and over. We switched to other laptops and observed the same issue. On desktops as well, different Windows systems. What we don't want to do is to reformat the whole thing and observe, because, really, the whole reason for this drive is for us to store large files in it as a backup, and not have a backup of backup. We have also switched settings to enable caching (and also to disable it) - same results. The drives are in NTFS and the USB drivers have been updated accordingly. We have check the disk, ran crystaldisk, WMIC, defrag (not really needed as these are fairly new), but all with same results. We dont find any similar issues online, of consistent active time spikes like we have shown you, so hopefully support can assist us as well.
After that, they still came back saying they needed more time with their engineers and kept asking us whether other activities were going on with the server and observing the disk was almost full. We did a full 6 page report for them, comparing crystaldiskinfo results of all our other drives (WD, Seagate) and point out specifically their disks were the ones having the spike issues and requested them again to check the controllers.
After days of delay, stating their engineers were looking into it, and our backups were stalled they came back with:
Regarding to the HDD speed performance, we kindly inform you that the speed (read/write) of products will be limited by different testing devices, software, components and testing platforms. The speed (read/write) of products is only for reference. From the print screen that you provide, we have to let you know that the write speed performance is slow because there are data stored in this drive. Kindly to be noted that the speed may vary when transferring huge data as storage drive or processing heavy working load as storage drive. Besides, please refer to the photo that we circled in red, both different drive have different data percentage. For our drive, the capacity is near full, then it is normal to see the write speed performance slower than other drive.
This response was baffling . It wasn’t just slow. It was unusable because there is data stored in this drive? Normal to see write speed slower?
After almost a week and half talking to this tech support, they surmise (with their engineers) that their drives cannot perform because there is data stored in it. It makes one wonder then why are disk drives created if not to store data.
Our final response was:
We respectfully disagree with you. Your drive is unusable with those crystaldisk numbers and I am sure everyone will agree to that. You are stating your drive is useless once it starts storing data, which is strange since your product is created to store data. Whether the drive is half full or completely full is not the point, we have run other drives which are 95% full and which are almost 100% full with no issues. Its your drive active time spiking up to 100% for unknown reasons, and we have not just one but two of your drives doing this. We have insisted you to look at the controller but it seems you have not been able to troubleshoot that. I believe you have gone the limit in your technical ability and you are simply unable to give anymore meaningful and useful support, and I don't think there's anything else you can do at that will be of use for us .We will have to mark it out as a product that we cannot purchase and revert back to other drives for future hard drive purchase and take note of your defective product to our partners.
And that was the end. Their tech support simply refused to assist and kept blaming a non-existent event (data are stored in the disk), which had absolutely zero logical sense. It was a BIZARRE tech conclusion that they came to and an absolute lesson of what not to do for tech support.
That being said, we temporary resolved the issue with a workaround by disabling one of our servers using UASP and force it to use BOT. This hack was taken from this link, so we don’t get the credit for this workaround.
Basically you go to C:\Windows\System32\drivers and just rename uaspstor.sys to uaspstor.sys.bk or whatever to back it up. Then copy usbstor.sys to uaspstor.sys.
Depending on your system, you might have to do this in safe mode. We managed to do it without. Reboot and plugged in the troublesome drive and now it works. Some other forums says to go to the registry and basically redirect the UASPStor Imagepath to usbstor.sys instead of uaspstor.sys. However, this is problematic as when you try to plugin a traditional external drive using BOT, it doesn’t get recognised, because we think that the usbstor.sys is locked for usage somehow. So having a usbstor.sys copied to uaspstor.sys seems to trick Windows into using the BOT drivers instead while thinking it’s using this troublesome UASP driver.
Now obviously this isn’t a solution, but it’s a workaround. For us, we just plug these drives into one of the older servers and used it as a temporary backup server until we figure out this thing in the long run.
But yeah, the lesson was really in our interaction with tech support and hopefully we all get better because of this! For technical solutions and support, please drop us a email or the comment below and we will get to you quickly and in parallel (not sequentially)!

